
The Floor
Easy and commoditized
Templates and single steps. Anyone can do it, and you should. Hire no one for this.
Automation, grounded in your real data
You have tried the templates and the chatbots. They got you part of the way. The automations that actually move the needle are the ones grounded in your own data, and those are exactly the ones that break when you build them alone.
PhD systems thinker · 29 years · 350+ CEOs advised · $50M+ in incremental revenue
Jed’s intro video · embed here
Two minutes with Jed on what separates an automation that demos well from one you can actually rely on.
The real problem
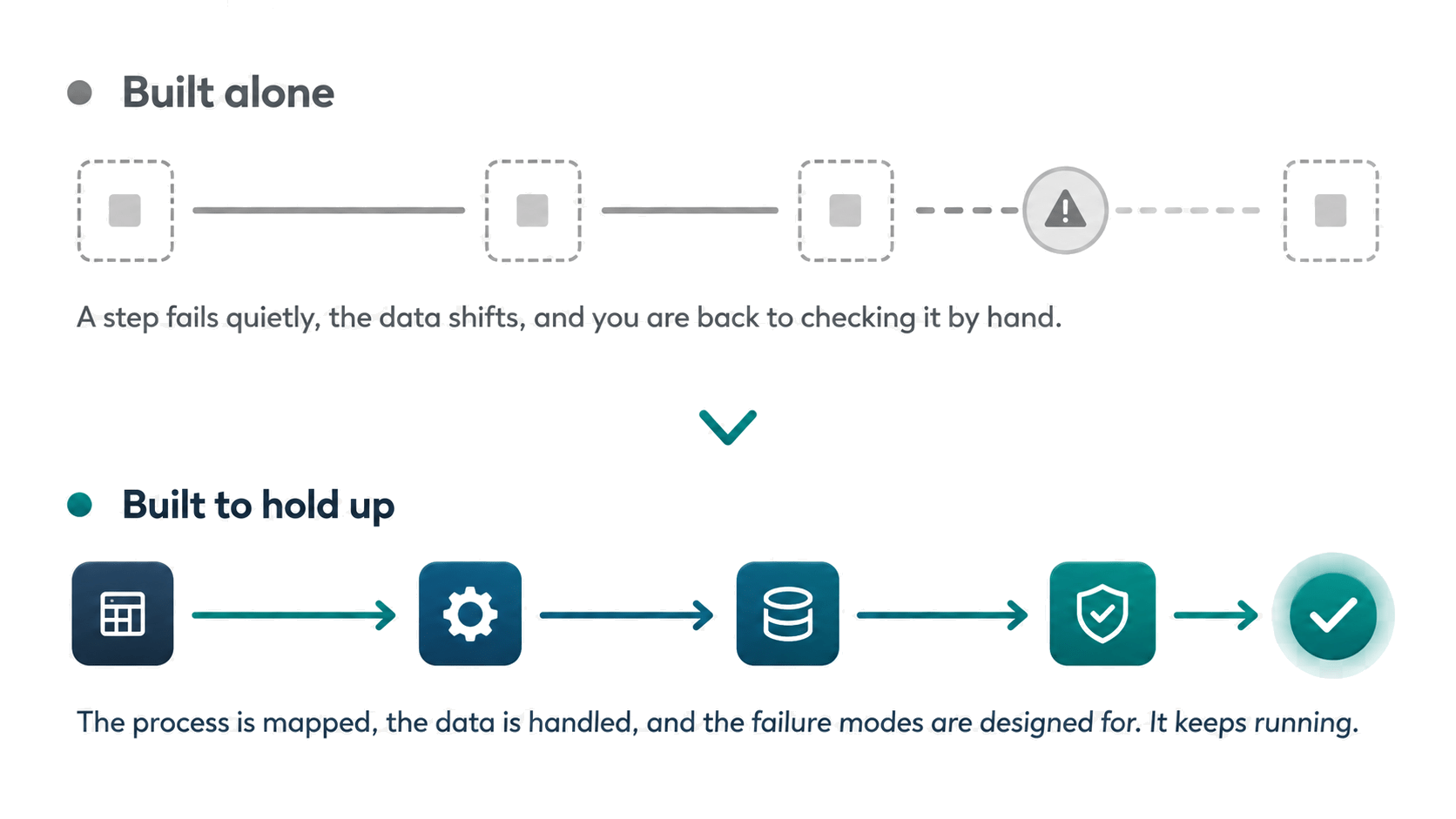
The tools are not the problem anymore. Almost anyone can wire two apps together or get a model to write something useful. The problem is that people automate a process they never actually mapped, so they end up with a faster version of a broken process.
Then the failure modes show up. The source data has a format nobody accounted for. A step fails and nothing tells you. The model changes under you. The automation that saved you an hour now costs you two, because you have to keep checking whether it is still right.
This is the gap we work in. Not the tool, the judgment about what to automate, how to handle the data, and how to build it so it survives contact with the real world.
Floor / Core / Beyond
The valuable automations are the ones that touch your real data. Those are exactly the ones DIY gets wrong, and exactly where we do our best work.
Templates and single steps. Anyone can do it, and you should. Hire no one for this.
Multi-step systems built on your own data, with the quality control that keeps them accurate. Genuinely valuable, genuinely hard.
✓ Where we work
If you truly need a standing engineering org of your own, you need to hire and run that team, not an advisor. We will tell you the moment you cross that line.
What we build
A sampling of real systems, grouped by what they do.
This is a partial list. The common thread is not the tool. It is a process mapped correctly, data handled properly, and quality control built in.
Take our 2-minute data-readiness assessment. Get a candid read on where automation would actually pay off for you, and where it would not.
Selected builds
25 months of treatment data, reconciled across multiple locations. The source system was full of inconsistent procedure codes. We ingested it, reconciled the codes, and built a dashboard tracking planned versus completed treatment value on a rolling 180-day basis.
Raw customer data turned into ranked personas with conversion, revenue, and value indexes. It is the analytical backbone behind our audience reports, and it runs the same way every time.
3 audiences, 150 contacts per campaign: scrape, enrich, human review, then outreach. Target companies are scraped, each enriched with AI research, then qualified and loaded to a database for human review before anything sends.
One oriented briefing in the inbox every morning, built from multiple sources overnight. An always-on chief of staff that reads everything so the day starts already in focus.
“I really appreciate having JLytics as an extension of my team, offering analytics guidance and execution. We work with JLytics to support our clients’ analytics programs, and this really helps us dig into actionable insights.”
“JLytics leveled up the analytics capabilities for my marketing team. The out-of-the-box Google Analytics 4 was not cutting it, so Jed and his team created customizations that made it much more useful for us.”
The differentiator
Above the surface, the tools look the same. The difference is everything underneath.

A tool in the wrong hands is just a faster way to make the wrong thing. My edge is the layer most automation help skips.
I spent more than twenty years running a data-driven marketing agency, hold a PhD in systems thinking and an MBA in marketing, and I build these systems myself. I map the real process before touching a tool, find the one leverage point worth automating, design for the ways it will break, and make it something a team can actually maintain.
And I can talk to your whole org, from a CEO on strategy and risk to the marketing team that runs the thing day to day. The conversation changes depending on who is in the room, and I have spent a career in all of those rooms.
Ownership model
The question most vendors avoid, answered up front. Three ways to own what we build.
Fixed scope, fixed price, clear deliverable. We design it, build it, and ship it.
We keep it monitored, patched, and accurate. For live data and RAG, this is how it stays trustworthy instead of quietly rotting.
Prefer to own it in-house? We document the system, train your team, and hand over the keys. Priced into the build.
An automation nobody is responsible for is just the DIY trap with extra steps. We will not leave you there.
How engagements work
Most clients start with a fixed-scope build so we can prove the work on one real process. From there we either move into a Run plan or expand into larger data and RAG systems. Bigger builds are scoped individually after a short discovery.
You always know what you are getting, what it costs, and who is responsible for keeping it running.
Engagements start with a two-week discovery at $3,999. Build and Run plans are quoted to fit, typically $500 to $5,000 per month. Larger data and RAG builds are scoped individually.
Questions
The best first conversation is concrete. Bring the process that wastes the most time, or the automation you started and could not finish. We will figure out whether it belongs on the floor, in our core, or with a team, and what it would take to do it right.
30 minutes, just you and Jed. No pitch, no pressure.
