

One of the powerful things about a foundation model like Claude or ChatGPT is that it ships with access to the world’s knowledge. Or at least that’s how it seems.
The catch is that models are trained up to a certain point in time, and then they go slightly stale in the months that follow. The builder can patch this with updates. The model can also patch it with a built-in web search feature that goes out, pulls the latest from the open web, and merges it with what the model already knows. There you go. Your response is current.
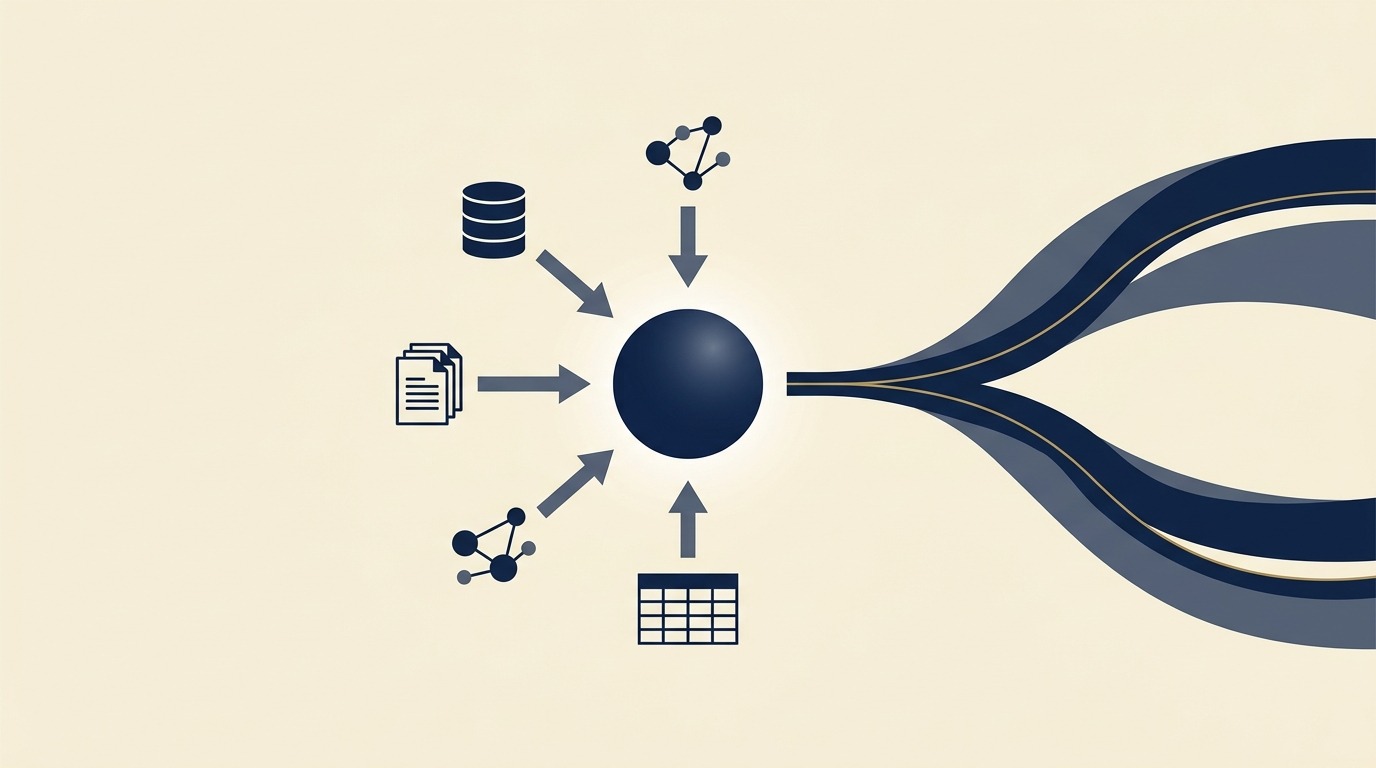
But what do you do when you want to merge your own data with your LLM? Your accounting records. Your CRM. Your customer data. Your transaction databases. Your internal notes. Your research studies. And more.
That’s where retrieval-augmented generation (RAG) comes in. Simplified, RAG marries your normal workflow and your foundation model with access to your own data. The important part is retrieving that data in a way that’s easy to retrieve. You don’t want to spend all your time reorganizing files, because that pulls you out of workflow. And you have to balance three competing concerns: accuracy, security, and speed.
In this post we’ll lay out your options for building a RAG system across two axes: retrieval and source format.
Retrieval has to do with how your system finds the right internal data from your team or your company history and passes it back to the model to fold into a response. Source format has to do with how that data is stored, which shapes everything from security to speed of recovery to accuracy.
These are not always discrete categories. Plenty of real systems are hybrids of more than one. But separating them this way gives you a clean conceptual map. Let’s walk the retrieval options first, then the format options, so you have a better sense of what to look for when you build your own.
Axis 1: Retrieval (how the system finds your data)
Think of retrieval methods on a spectrum from literal to relational, with each step adding semantic richness.
Lexical. The floor. Simple string matching (grep) finds exact text. The grown-up version is BM25 or full-text search (Postgres FTS, Elasticsearch), which weights terms by relevance. Lexical wins when queries are literal: product codes, account numbers, proper names. Its limit is that it has zero understanding of meaning.
Structured. When your data already has a schema, let the model query it directly. Text-to-SQL turns a plain-English question into a database query. This is the only method that does precise aggregation, filtering, and numeric answers well. Its limit is that it only works on structured stores.
Dense. Vector embeddings retrieve by meaning rather than by keyword. You chunk your documents, embed them, and search by semantic similarity (commonly with pgvector). This is what lets “cancellation policy” match a paragraph that never uses that phrase. Its failure mode is that it retrieves what’s similar, which is not always what’s correct.
Graph. Knowledge graphs and GraphRAG retrieve by relationship. They traverse entities and connections, which enables multi-hop reasoning the other three cannot do. Graph is its own category, but in practice it’s usually deployed in hybrid: vectors find the entry points, then the graph expands from them.
Cross-cutting layers. A few techniques stack on top of all of the above rather than competing with them. Hybrid search fuses lexical and dense results. Reranking adds a second-stage model that reorders your top results. Metadata filtering narrows by date, source, or tenant before retrieval runs. Agentic retrieval lets the model decide what to query, and query again, until it has what it needs.
Axis 2: Source Format (how your data is stored)
The retrieval method runs over a format, so the format constrains what’s even possible.
- Plain text and Markdown. The simplest substrates. Easy to chunk, easy to embed, friendly to every retrieval method.
- HTML. Common for scraped or web-native content. Requires parsing to strip markup before retrieval.
- PDF. Ubiquitous and messy. Tables, scans, and multi-column layouts all need careful extraction first.
- Structured and tabular. SQL tables, CSV, Parquet. The natural home for text-to-SQL.
- Semi-structured. JSON, XML, YAML. Flexible, and often the bridge between raw documents and a queryable store.
- Graph stores. Neo4j, RDF triples. Required if you want true graph traversal, though you can also extract a knowledge graph out of the formats above.
Not every pairing is valid. Text-to-SQL needs structure. Graph traversal needs a graph. Lexical and dense work on almost anything once you parse and chunk it. Match the method to the format, layer where it helps, and you have a RAG system that fits your workflow instead of fighting it.
The catch is that the right design depends on what your data actually looks like today, and most teams have not mapped that honestly. If you want a partner to design a retrieval system around your real data instead of a generic template, that is what we do.
Book an Executive Data Assessment and let’s map what you have and what it would take.
